API Concepts
SOA? RPC? ESB?
Service Oriented Architecture (SOA) is fuzzy term, describing architectural style, not exact implementation. It’s more of a logical, and not a physical concept.
At its core, SOA means separating software into isolated components (“services”) that are accessed through well-defined interfaces. Components in SOA system communicate using a network protocol.
In practical terms, this means that changes can be made to a service without affecting its other parts of a system (clients = consumers of a service), as long as the protocol remains compatible.
Further reading


Basic Concepts
The Broker. We call it API.
We already defined our logical structure. It’s a centralized point (Router or API or whatever we call it) where all request are destined to. In SOA terminology, this central system is called the broker. If you by accident stumble on a term ESB (Enterprise Service Bus) somewhere on the internet, you should known that in essence, it’s the same term as broker.
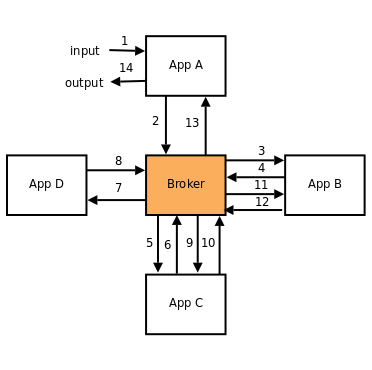
Drawbacks of broker model
- Excessive amount of network communication will at some time lead to network congestion
- All messages have to be passed through the broker, so broker can become bottleneck of the whole system (Broker Congestion)
- There is a single point of failure
Evolution of a broker = No broker
We are ambitious. We want to resolve all broker’s problems. And we believe that we can do it. And we will analyze it in steps, to simplify thing. And to explain every step of this reasoning.
Look ma – no brokers
To solve the first (and second, and third) broker-model’s problem, we will totally bypass broker in inter-system communications. In this way, we will significantly reduce amount of network communication. Just count the number of message routes in our illustration – it dropped more than three-fold, from 14 to 5.
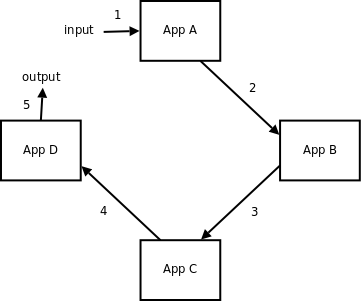
New problems
By avoiding broker, we solved almost every problem we had, but we managed to create a new one. And, this is because each application (service) has to connect to the another application directly and thus it has to know it’s network address (ip:port).
In small deployments, some kind of static service discovery mechanism is acceptable, but in not real-time self-reliant clusters.
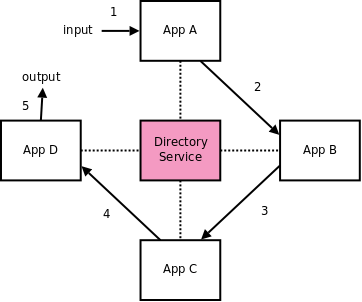
Let’s go back to broker concept, and explain it a bit more. Note that we can split the functionality of the broker into two separate parts:
-
broker has a repository of applications running on the network.
It knows that application X runs on host Y and that messages intended for X should be sent to Y. Broker acts like a directory service -
broker does the message transfer itself, implementing message queue
This also means that sender and receiver don’t have to have overlapped lifetimes. Messages are stored in the broker while sender is already off and receiver has not yet started. If the application fails, the messages destined for that application that were already passed to the broker are not lost.
We will implement both of these functionalities, but this time without without broker as single point of failure.
Decentralize Message Queue
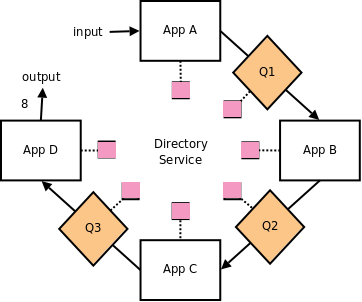
On this new diagram, each message queue is implemented as a separate service. It can or can’t run on the same physical box as one of the applications it is connecting.
Queue is registered with the broker (directory service) and thus it is accessible to all the applications on the network. It is very simple piece of software that’s getting messages from senders and distributing them to the receivers.
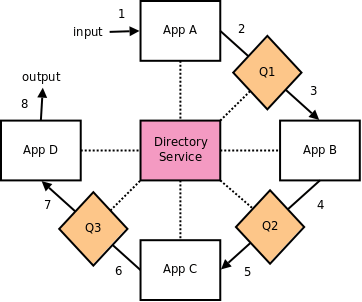
Decentralize Directory Service
We still have to avoid single point of failure. And directory service is still single point. To solve this problem we need a distributed directory service.
Small squares on the picture represent the copies of configuration of services (list of addresses and services).
Failure of a single node – this centralized services directory, now will not stop all the processing. Even if one node goes completely off-line, processing in the system will not stop.
Besides that, the networking topology is constantly evolving. New systems are added, old ones are dumped. New services are deployed, old ones are discarded. New network links are being established etc. This distributed directory service must adapt to these changes, in real-time.
Further reading
- Broker vs. Brokerless – reasoning behind ZeroMQ.
Broker-less: it’s not hard
Thanks to the open-source movement and companies like Facebook, Yahoo, etc, the implementation of this broker-less architecture is already available, tested and documented to some extent. These are building-blocks of broker-less architecture:
- RPC framework in a form of libraries
-
Should provide some serialization protocol (XML, JSON, BSON - Binary JSON, MessagePack, Thrift, Protobuf, etc). With this protocol, data is send back and forth, encoded and decoded, even stored (alas, it’s not intended to), so it must be efficient both in size and in speed.
-
We need a standardized way of defining services and its parameters, usually some specialized quasi-language. Technically, this specification is called IDL as “interface description language”
-
Has to operate (“bind”) with different systems and different programming languages
-
Transport Mechanism (Message Queues)
-
Service Discovery System (Distributed Discovery System)
-
External API
Exposing an API outside of system / external API This is no-brainer: REST is de-facto standard. It’s too slow for internal usage, but fast enough for external. You could use expose internal RPC call to outside (like Evernote did with theirs API based on Thrift), but it’s considered not-secure enough, at least in PHP binding.
Further reading